

Sponsored content by emmtrix Technologies GmbH

Software parallelisieren? Mit emmtrix klappt das!
Um das volle Leistungspotential moderner Mehrkernprozessoren nutzen zu können, muss die Software auf die Rechenkerne verteilt werden. Diese schwierige, fehleranfällige und zeitraubende Aufgabe wird heute in der Regel manuell von den Entwicklern erledigt, zumeist ohne zusätzliche Softwareunterstützung bei Analyse und Umsetzung. Die Firma emmtrix Technologies bietet mit emmtrix Parallel Studio eine umfassende Lösung an, mit der Entwickler modellbasierte Anwendungen aus MATLAB® oder Simulink® sowie C-Programme mit wenigen Klicks für aktuelle, parallele Prozessorarchitekturen parallelisieren können. Der automatisch erzeugte, qualifizierbare C-Code ermöglicht in Kombination mit sicherheitszertifizierter Hardware wie dem Infineon AURIX™ Mikrocontroller die Umsetzung funktional sicherer Systeme nach ISO 26262 und DO-178C.
Wieso Parallelisierung?
Bereits seit einigen Jahren werden große Performanzsprünge bei Prozessoren vornehmlich dadurch erreicht, dass immer mehr Prozessorkerne integriert werden, die eine parallele Verarbeitung mehrerer Aufgaben ermöglichen. Diese Entwicklung erreicht nun auch eingebettete Mikrocontroller für sicherheitskritische Systeme, wie etwa den Infineon AURIX™ Mikrocontroller. Während die erste Generation noch bis zu drei Kerne hatte, stehen in der aktuellen zweiten Generation bis zu sechs Kerne zur Verfügung und die kommende Generation wird einen digitalen Signalprozessor zur Beschleunigung von Vektoroperationen bereitstellen. Bestehende Software-Designs profitieren jedoch nicht automatisch von der zusätzlichen Rechenleistung, die zusätzlichen Kerne bleiben zunächst ungenutzt. Erst durch Parallelisierung – das Verteilen von Teilaufgaben auf verschiedene Kerne – lässt sich das volle Potential des Systems nutzen.
Angesichts steigender Anforderungen stellt sich häufig die Frage, ob Datendurchsatz und Antwortzeiten mit der Nutzung eines einzelnen Kernes noch erfüllt werden können. Statt nun mit viel Aufwand die Software für viele Kerne neu zu entwerfen, bietet sich eine nachgeordnete Parallelisierung an – aus sequentiellem wird paralleler Code. Dieser Schritt ist jedoch ohne Automatisierung nicht trivial.
Warum ist parallele Programmierung so komplex?
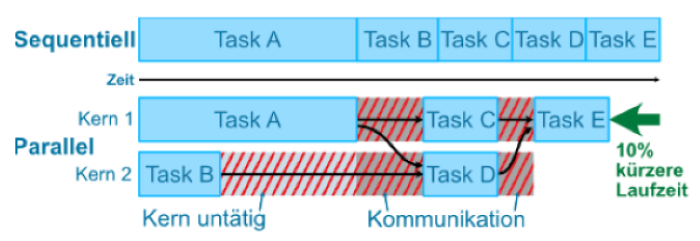 Abbildung 1 Ineffiziente Parallelisierung durch unabgestimmte Task-Ausführungszeiten und Kommunikation
Eines der grundlegenden Probleme der Parallelisierung ist, dass sich nicht alle Aufgaben gleichermaßen für die parallele Verarbeitung eignen und dass ein paralleles Programm in der Regel nicht auf eine beliebige Anzahl an Kernen skaliert werden kann. Aufgaben, die ohne großen Rechenaufwand häufig Zwischenergebnisse produzieren, sind dafür ein häufig auftretendes Beispiel. Abbildung 1 stellt den zeitlichen Verlauf der Ausführung von fünf Tasks (A bis E) sequenziell auf einem Prozessorkern und parallelisiert auf zwei Prozessorkernen gegenüber. Zum einen sorgt die unterschiedliche Laufzeit von A und B dafür, dass Kern 2 nach der Abarbeitung von B für längere Zeit untätig bleibt. Des Weiteren ist die Bereitstellung von Ergebnissen von einem Kern zum andern mit Kommunikationsaufwand verbunden, der umso mehr ins Gewicht fällt, je kürzer die Laufzeiten der einzelnen Tasks sind. Folglich lässt sich in diesem Beispiel lediglich eine um 10% verkürzte Laufzeit erreichen, was angesichts der eingesetzten Hardware und der theoretisch möglichen Verdopplung der Performanz zunächst enttäuscht.
Abbildung 1 Ineffiziente Parallelisierung durch unabgestimmte Task-Ausführungszeiten und Kommunikation
Eines der grundlegenden Probleme der Parallelisierung ist, dass sich nicht alle Aufgaben gleichermaßen für die parallele Verarbeitung eignen und dass ein paralleles Programm in der Regel nicht auf eine beliebige Anzahl an Kernen skaliert werden kann. Aufgaben, die ohne großen Rechenaufwand häufig Zwischenergebnisse produzieren, sind dafür ein häufig auftretendes Beispiel. Abbildung 1 stellt den zeitlichen Verlauf der Ausführung von fünf Tasks (A bis E) sequenziell auf einem Prozessorkern und parallelisiert auf zwei Prozessorkernen gegenüber. Zum einen sorgt die unterschiedliche Laufzeit von A und B dafür, dass Kern 2 nach der Abarbeitung von B für längere Zeit untätig bleibt. Des Weiteren ist die Bereitstellung von Ergebnissen von einem Kern zum andern mit Kommunikationsaufwand verbunden, der umso mehr ins Gewicht fällt, je kürzer die Laufzeiten der einzelnen Tasks sind. Folglich lässt sich in diesem Beispiel lediglich eine um 10% verkürzte Laufzeit erreichen, was angesichts der eingesetzten Hardware und der theoretisch möglichen Verdopplung der Performanz zunächst enttäuscht.
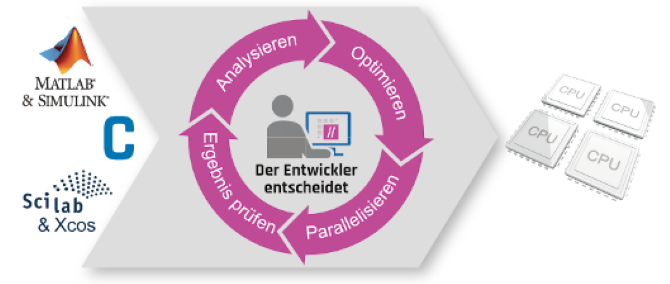 Abbildung 2 Parallelisierungs-Workflow mit emmtrix Parallel Studio
Die Parallelisierung bestehender Software erfordert mehrere Teilschritte, die zumeist mehrmals, iterativ durchlaufen werden, bis das Programm die zeitlichen Anforderungen erfüllt. Der interaktive Parallelisierungs-Workflow von emmtrix Parallel Studio bildet diesen Zyklus wie in Abbildung 2 dargestellt ab und unterstützt den Entwickler in jeder Phase des Prozesses, von der Analyse der Anwendung über die Optimierung bis zur Verteilung auf die Kerne und die automatische Erzeugung des parallelen Programms. Hierbei behält der Entwickler stets den Überblick sowie die volle Kontrolle, und das, ohne auch nur eine Zeile Code schreiben zu müssen.
Abbildung 2 Parallelisierungs-Workflow mit emmtrix Parallel Studio
Die Parallelisierung bestehender Software erfordert mehrere Teilschritte, die zumeist mehrmals, iterativ durchlaufen werden, bis das Programm die zeitlichen Anforderungen erfüllt. Der interaktive Parallelisierungs-Workflow von emmtrix Parallel Studio bildet diesen Zyklus wie in Abbildung 2 dargestellt ab und unterstützt den Entwickler in jeder Phase des Prozesses, von der Analyse der Anwendung über die Optimierung bis zur Verteilung auf die Kerne und die automatische Erzeugung des parallelen Programms. Hierbei behält der Entwickler stets den Überblick sowie die volle Kontrolle, und das, ohne auch nur eine Zeile Code schreiben zu müssen.
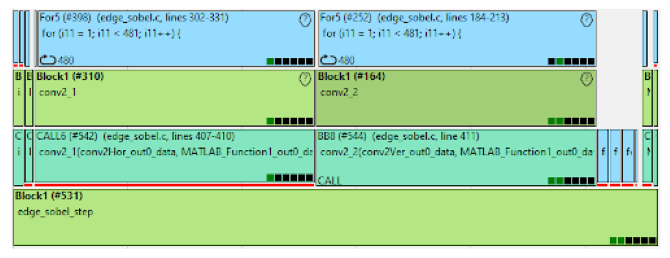 Abbildung 3 Analyse und Identifizierung von Hotspots
Am Anfang steht die Analyse der Anwendung: Zunächst gilt es herauszufinden, welche Laufzeit die einzelnen Teile des Programms haben und welche Teile beschleunigt werden müssen, damit das Gesamtprogramm die Zeitanforderungen einhält. emmtrix Parallel Studio unterstützt den Entwickler hierbei durch eine grafische Darstellung des Eingangsprogramms wie in Abbildung 3 dargestellt: jeder Block beschreibt eine Teilkomponente des Gesamtprogramms. Von unten nach oben wird die Struktur des Programms zunehmend feiner aufgelöst. Der zeitliche Verlauf der Programmausführung ist entlang der horizontalen Achse ersichtlich. Je breiter ein Block ist, desto länger ist seine Laufzeit. In der Mitte der Abbildung sind zwei Funktionen, conv2_1 und conv2_2 zu sehen. Man erkennt, dass die Funktion conv2_2 hauptsächlich aus einer Schleife besteht, die mit For5 bezeichnet ist und die Laufzeit der Funktion dominiert. Die ermittelten Ausführungszeiten basieren auf einem Modell des eingesetzten Prozessors, so dass leicht ersichtlich wird, welche Teile des Programms dessen Laufzeit auf dem Zielsystem bestimmen und wo es sich folglich lohnt, mit der Parallelisierung zu beginnen.
Nachdem auf diese Weise schnell die kritischen Teile des Programms identifiziert sind, müssen nun unabhängige Tasks gefunden und ausgewählt werden, um sie auf die Kerne zu verteilen. In bestehendem Code werden meist Konstrukte eingesetzt, welche die Erkennung nebenläufiger Tasks behindern und somit deren parallele Verteilung erschweren. Hierzu gehören beispielsweise Zeiger und globale Variablen. Die Analyse und manuelle Restrukturierung solcher Programme für die Parallelisierung ist ein zeitraubendes und fehleranfälliges Unterfangen. Dieser Aufwand entfällt bei Verwendung von emmtrix Parallel Studio komplett, weil es die Abhängigkeiten zwischen den Tasks automatisch erkennt und dem Anwender grafisch anzeigt. Basierend auf dieser Analyse bekommt der Entwickler eine Auswahl an Transformationen angeboten, mit denen das ursprüngliche Programm so umstrukturiert werden kann, dass mehr Nebenläufigkeit entsteht. Der Entwickler wählt lediglich die Transformation aus. Die Umsetzung durch Umschreiben des Codes geschieht dann vollautomatisch durch emmtrix Parallel Studio, so dass sich hier keine Fehler einschleichen können. Ein wichtiger Baustein sind Schleifenoptimierungen.
Abbildung 3 Analyse und Identifizierung von Hotspots
Am Anfang steht die Analyse der Anwendung: Zunächst gilt es herauszufinden, welche Laufzeit die einzelnen Teile des Programms haben und welche Teile beschleunigt werden müssen, damit das Gesamtprogramm die Zeitanforderungen einhält. emmtrix Parallel Studio unterstützt den Entwickler hierbei durch eine grafische Darstellung des Eingangsprogramms wie in Abbildung 3 dargestellt: jeder Block beschreibt eine Teilkomponente des Gesamtprogramms. Von unten nach oben wird die Struktur des Programms zunehmend feiner aufgelöst. Der zeitliche Verlauf der Programmausführung ist entlang der horizontalen Achse ersichtlich. Je breiter ein Block ist, desto länger ist seine Laufzeit. In der Mitte der Abbildung sind zwei Funktionen, conv2_1 und conv2_2 zu sehen. Man erkennt, dass die Funktion conv2_2 hauptsächlich aus einer Schleife besteht, die mit For5 bezeichnet ist und die Laufzeit der Funktion dominiert. Die ermittelten Ausführungszeiten basieren auf einem Modell des eingesetzten Prozessors, so dass leicht ersichtlich wird, welche Teile des Programms dessen Laufzeit auf dem Zielsystem bestimmen und wo es sich folglich lohnt, mit der Parallelisierung zu beginnen.
Nachdem auf diese Weise schnell die kritischen Teile des Programms identifiziert sind, müssen nun unabhängige Tasks gefunden und ausgewählt werden, um sie auf die Kerne zu verteilen. In bestehendem Code werden meist Konstrukte eingesetzt, welche die Erkennung nebenläufiger Tasks behindern und somit deren parallele Verteilung erschweren. Hierzu gehören beispielsweise Zeiger und globale Variablen. Die Analyse und manuelle Restrukturierung solcher Programme für die Parallelisierung ist ein zeitraubendes und fehleranfälliges Unterfangen. Dieser Aufwand entfällt bei Verwendung von emmtrix Parallel Studio komplett, weil es die Abhängigkeiten zwischen den Tasks automatisch erkennt und dem Anwender grafisch anzeigt. Basierend auf dieser Analyse bekommt der Entwickler eine Auswahl an Transformationen angeboten, mit denen das ursprüngliche Programm so umstrukturiert werden kann, dass mehr Nebenläufigkeit entsteht. Der Entwickler wählt lediglich die Transformation aus. Die Umsetzung durch Umschreiben des Codes geschieht dann vollautomatisch durch emmtrix Parallel Studio, so dass sich hier keine Fehler einschleichen können. Ein wichtiger Baustein sind Schleifenoptimierungen.
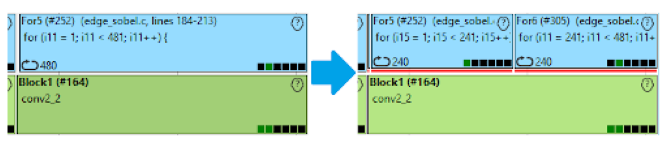 Abbildung 4 Schleifentransformation
Abbildung 4 zeigt, wie sich die Transformation „Loop Splitting“ auf die Schleife For5 auswirkt: sie wird in zwei Schleifen For5 und For6 mit jeweils dem halben Iterationsbereich aufgeteilt, die später von verschiedenen Kernen ausgeführt werden können.
Abbildung 4 Schleifentransformation
Abbildung 4 zeigt, wie sich die Transformation „Loop Splitting“ auf die Schleife For5 auswirkt: sie wird in zwei Schleifen For5 und For6 mit jeweils dem halben Iterationsbereich aufgeteilt, die später von verschiedenen Kernen ausgeführt werden können.
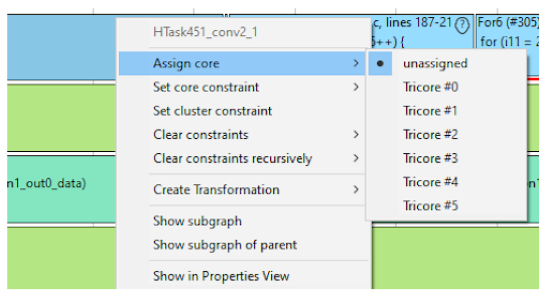 Abbildung 5 Feste Zuordnung von Tasks zu Kernen oder Ausschluss von Kernen von der Parallelisierung
Nachdem im vorherigen Schritt unabhängige Tasks identifiziert bzw. durch Transformationen geschaffen wurden, gilt es nun, diese so auf die Kerne zu verteilen, dass diese gut ausgelastet sind und möglichst wenige Daten zwischen den Kernen ausgetauscht werden müssen. Hierfür kommt ein automatischer Verteilungsalgorithmus zum Einsatz, der spezifische Eigenschaften der Zielarchitektur berücksichtigt. Er kennt den internen Aufbau des Prozessors, wie etwa die Anbindung von Speichern an die Prozessorkerne, und dessen Einfluss auf die Kommunikationskosten und somit die optimale Verteilung der Tasks. Beim AURIX™-Mikrocontroller sind beispielsweise die Kerne in zwei Cluster aufgeteilt. Der Datenaustausch zwischen Kernen verschiedener Cluster ist langsamer als zwischen Kernen eines Clusters. Deshalb sollten Tasks, die häufig Daten austauschen müssen, auf Kernen desselben Clusters verteilt werden. Auch wenn die Verteilung der Tasks zunächst vollautomatisch geschieht, kann der Entwickler in den Parallelisierungsprozess eingreifen, indem er Tasks an bestimmte Kerne heftet oder bestimmte Kerne von der Verteilung ausschließt. Dies geschieht wie in Abbildung 5 dargestellt über die grafische Benutzeroberfläche oder durch Annotationen im Eingangscode. Dadurch behält der Entwickler die volle Kontrolle und kann mit seinem Wissen über die Anwendung die Feinabstimmung des Ergebnisses übernehmen.
Abbildung 5 Feste Zuordnung von Tasks zu Kernen oder Ausschluss von Kernen von der Parallelisierung
Nachdem im vorherigen Schritt unabhängige Tasks identifiziert bzw. durch Transformationen geschaffen wurden, gilt es nun, diese so auf die Kerne zu verteilen, dass diese gut ausgelastet sind und möglichst wenige Daten zwischen den Kernen ausgetauscht werden müssen. Hierfür kommt ein automatischer Verteilungsalgorithmus zum Einsatz, der spezifische Eigenschaften der Zielarchitektur berücksichtigt. Er kennt den internen Aufbau des Prozessors, wie etwa die Anbindung von Speichern an die Prozessorkerne, und dessen Einfluss auf die Kommunikationskosten und somit die optimale Verteilung der Tasks. Beim AURIX™-Mikrocontroller sind beispielsweise die Kerne in zwei Cluster aufgeteilt. Der Datenaustausch zwischen Kernen verschiedener Cluster ist langsamer als zwischen Kernen eines Clusters. Deshalb sollten Tasks, die häufig Daten austauschen müssen, auf Kernen desselben Clusters verteilt werden. Auch wenn die Verteilung der Tasks zunächst vollautomatisch geschieht, kann der Entwickler in den Parallelisierungsprozess eingreifen, indem er Tasks an bestimmte Kerne heftet oder bestimmte Kerne von der Verteilung ausschließt. Dies geschieht wie in Abbildung 5 dargestellt über die grafische Benutzeroberfläche oder durch Annotationen im Eingangscode. Dadurch behält der Entwickler die volle Kontrolle und kann mit seinem Wissen über die Anwendung die Feinabstimmung des Ergebnisses übernehmen.
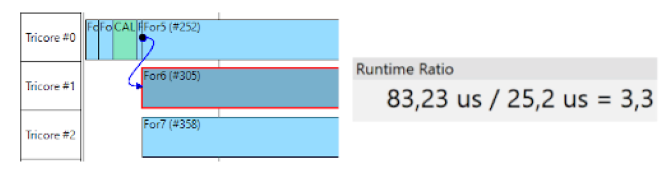 Abbildung 6 Abschätzung der Performanz des parallelen Programms
Nach Abschluss der Parallelisierung stellt sich die Frage, welche Beschleunigung durch die Parallelisierung erreicht wurde und ob die Anwendung nun die Anforderungen erfüllt. emmtrix Parallel Studio unterstützt den Entwickler bei der Analyse der parallelen Performanz durch Abschätzung der parallelen Laufzeit und der erreichten Beschleunigung sowie mit einer visuellen Darstellung des zeitlichen Programmablaufs wie in Abbildung 6 dargestellt. Die Abschätzung basiert auf dem Hardware- und Softwaremodell des Zielsystems und kann durch Simulation oder direkt durch Ausführung auf der Zielarchitektur verfeinert werden, so dass der Entwickler sofort ein Gefühl für die zu erwartende Beschleunigung bekommt.
Der Entwickler steuert diesen automatisierten Prozess durch seine Entscheidungen – das Anwenden von Transformationen und Festlegen von Kernen für bestimmte Tasks, ohne dass auch nur eine Zeile Code angefasst werden muss. Die eingesparte Implementierungszeit kann dazu verwendet werden, den Prozess mehrfach zu durchlaufen und die Auswirkungen verschiedener Entscheidungen auf die Performanz der Anwendung zu evaluieren. Dadurch kann ohne Spezialwissen über parallele Programmierung und das Zielsystem effizient und erfolgreich parallelisiert werden.
Am Ende dieses Prozesses erzeugt emmtrix Parallel Studio vollautomatisch korrekten parallelen Code für das gewählte Zielsystem, der auch die Kommunikation und Synchronisation zwischen den Kernen übernimmt. Dadurch werden Fehler, die bei der manuellen Parallelisierung typischerweise auftreten, von vorneherein ausgeschlossen – die zeitraubende Suche nach Deadlocks und Race Conditions entfällt.
Abbildung 6 Abschätzung der Performanz des parallelen Programms
Nach Abschluss der Parallelisierung stellt sich die Frage, welche Beschleunigung durch die Parallelisierung erreicht wurde und ob die Anwendung nun die Anforderungen erfüllt. emmtrix Parallel Studio unterstützt den Entwickler bei der Analyse der parallelen Performanz durch Abschätzung der parallelen Laufzeit und der erreichten Beschleunigung sowie mit einer visuellen Darstellung des zeitlichen Programmablaufs wie in Abbildung 6 dargestellt. Die Abschätzung basiert auf dem Hardware- und Softwaremodell des Zielsystems und kann durch Simulation oder direkt durch Ausführung auf der Zielarchitektur verfeinert werden, so dass der Entwickler sofort ein Gefühl für die zu erwartende Beschleunigung bekommt.
Der Entwickler steuert diesen automatisierten Prozess durch seine Entscheidungen – das Anwenden von Transformationen und Festlegen von Kernen für bestimmte Tasks, ohne dass auch nur eine Zeile Code angefasst werden muss. Die eingesparte Implementierungszeit kann dazu verwendet werden, den Prozess mehrfach zu durchlaufen und die Auswirkungen verschiedener Entscheidungen auf die Performanz der Anwendung zu evaluieren. Dadurch kann ohne Spezialwissen über parallele Programmierung und das Zielsystem effizient und erfolgreich parallelisiert werden.
Am Ende dieses Prozesses erzeugt emmtrix Parallel Studio vollautomatisch korrekten parallelen Code für das gewählte Zielsystem, der auch die Kommunikation und Synchronisation zwischen den Kernen übernimmt. Dadurch werden Fehler, die bei der manuellen Parallelisierung typischerweise auftreten, von vorneherein ausgeschlossen – die zeitraubende Suche nach Deadlocks und Race Conditions entfällt.
 Abbildung 7 Qualifizierung nach ISO 26262 und DO-178C - emmtrix Safety Kit
Bei der Qualifizierung paralleler Systeme nach ISO 26262 oder DO-178C gibt es einige zusätzliche Hürden, sowohl bei der Hardware als auch bei der parallelen Software. So ist der Infineon AURIX™ ist einer der wenigen Mehrkern-Mikrocontroller, der für funktional sichere Systeme nach ASIL D zertifiziert ist. Der Nachweis der funktionalen Sicherheit ist speziell für manuell geschriebene parallele Software schwer zu erbringen, denn allein die Abwesenheit von Deadlocks und Race Conditions, die unter Umständen nur sporadisch zu fatalen Fehlern führen können, ist selbst mit ausgiebigen Tests nicht mit letzter Sicherheit nachzuweisen. Hier setzt das emmtrix Safety Kit an: es liefert einen formalen Beweis, dass der automatisch generierte parallele Code mit dem ursprünglichen Code funktional identisch ist. Dadurch ist sichergestellt, dass die parallele Anwendung denselben Sicherheitsansprüchen genügt wie das qualifizierte Ursprungsprogramm.
Haben wir Ihr Interesse geweckt?
Dann nehmen Sie doch Kontakt zu uns auf! Wir unterstützen Sie gerne bei Ihrem nächsten Multicore-Projekt. Am 05. und am 19. November 2020 bieten wir Ihnen ein kostenloses AURIX™ Webinar auf Englisch an, bei dem wir beispielhaft an einer Anwendung demonstrieren, wie einfach es mit Hilfe von emmtrix Parallel Studio ist, Software für Infineon 32-bit TriCore™ AURIX™ TC2xx und TC3xx Mikrocontroller zu parallelisieren und dadurch die volle Leistung des Systems zu nutzen.
Hier geht es zur Anmeldung.
Abbildung 7 Qualifizierung nach ISO 26262 und DO-178C - emmtrix Safety Kit
Bei der Qualifizierung paralleler Systeme nach ISO 26262 oder DO-178C gibt es einige zusätzliche Hürden, sowohl bei der Hardware als auch bei der parallelen Software. So ist der Infineon AURIX™ ist einer der wenigen Mehrkern-Mikrocontroller, der für funktional sichere Systeme nach ASIL D zertifiziert ist. Der Nachweis der funktionalen Sicherheit ist speziell für manuell geschriebene parallele Software schwer zu erbringen, denn allein die Abwesenheit von Deadlocks und Race Conditions, die unter Umständen nur sporadisch zu fatalen Fehlern führen können, ist selbst mit ausgiebigen Tests nicht mit letzter Sicherheit nachzuweisen. Hier setzt das emmtrix Safety Kit an: es liefert einen formalen Beweis, dass der automatisch generierte parallele Code mit dem ursprünglichen Code funktional identisch ist. Dadurch ist sichergestellt, dass die parallele Anwendung denselben Sicherheitsansprüchen genügt wie das qualifizierte Ursprungsprogramm.
Haben wir Ihr Interesse geweckt?
Dann nehmen Sie doch Kontakt zu uns auf! Wir unterstützen Sie gerne bei Ihrem nächsten Multicore-Projekt. Am 05. und am 19. November 2020 bieten wir Ihnen ein kostenloses AURIX™ Webinar auf Englisch an, bei dem wir beispielhaft an einer Anwendung demonstrieren, wie einfach es mit Hilfe von emmtrix Parallel Studio ist, Software für Infineon 32-bit TriCore™ AURIX™ TC2xx und TC3xx Mikrocontroller zu parallelisieren und dadurch die volle Leistung des Systems zu nutzen.
Hier geht es zur Anmeldung.
 emmtrix Technologies GmbH
Haid-und-Neu-Str. 7
D-76131 Karlsruhe
Tel: +49 721 9861 4560
E-Mail:
Web: www.emmtrix.com
Autor:
emmtrix Technologies GmbH
Haid-und-Neu-Str. 7
D-76131 Karlsruhe
Tel: +49 721 9861 4560
E-Mail:
Web: www.emmtrix.com
Autor:
 Michael Rückauer
Senior Engineer
emmtrix Technologies
________________________________________________________________________________________
Michael Rückauer
Senior Engineer
emmtrix Technologies
________________________________________________________________________________________
Abbildung 1 Ineffiziente Parallelisierung durch unabgestimmte Task-Ausführungszeiten und Kommunikation
Eines der grundlegenden Probleme der Parallelisierung ist, dass sich nicht alle Aufgaben gleichermaßen für die parallele Verarbeitung eignen und dass ein paralleles Programm in der Regel nicht auf eine beliebige Anzahl an Kernen skaliert werden kann. Aufgaben, die ohne großen Rechenaufwand häufig Zwischenergebnisse produzieren, sind dafür ein häufig auftretendes Beispiel. Abbildung 1 stellt den zeitlichen Verlauf der Ausführung von fünf Tasks (A bis E) sequenziell auf einem Prozessorkern und parallelisiert auf zwei Prozessorkernen gegenüber. Zum einen sorgt die unterschiedliche Laufzeit von A und B dafür, dass Kern 2 nach der Abarbeitung von B für längere Zeit untätig bleibt. Des Weiteren ist die Bereitstellung von Ergebnissen von einem Kern zum andern mit Kommunikationsaufwand verbunden, der umso mehr ins Gewicht fällt, je kürzer die Laufzeiten der einzelnen Tasks sind. Folglich lässt sich in diesem Beispiel lediglich eine um 10% verkürzte Laufzeit erreichen, was angesichts der eingesetzten Hardware und der theoretisch möglichen Verdopplung der Performanz zunächst enttäuscht.
Abbildung 2 Parallelisierungs-Workflow mit emmtrix Parallel Studio
Die Parallelisierung bestehender Software erfordert mehrere Teilschritte, die zumeist mehrmals, iterativ durchlaufen werden, bis das Programm die zeitlichen Anforderungen erfüllt. Der interaktive Parallelisierungs-Workflow von emmtrix Parallel Studio bildet diesen Zyklus wie in Abbildung 2 dargestellt ab und unterstützt den Entwickler in jeder Phase des Prozesses, von der Analyse der Anwendung über die Optimierung bis zur Verteilung auf die Kerne und die automatische Erzeugung des parallelen Programms. Hierbei behält der Entwickler stets den Überblick sowie die volle Kontrolle, und das, ohne auch nur eine Zeile Code schreiben zu müssen.
Abbildung 3 Analyse und Identifizierung von Hotspots
Am Anfang steht die Analyse der Anwendung: Zunächst gilt es herauszufinden, welche Laufzeit die einzelnen Teile des Programms haben und welche Teile beschleunigt werden müssen, damit das Gesamtprogramm die Zeitanforderungen einhält. emmtrix Parallel Studio unterstützt den Entwickler hierbei durch eine grafische Darstellung des Eingangsprogramms wie in Abbildung 3 dargestellt: jeder Block beschreibt eine Teilkomponente des Gesamtprogramms. Von unten nach oben wird die Struktur des Programms zunehmend feiner aufgelöst. Der zeitliche Verlauf der Programmausführung ist entlang der horizontalen Achse ersichtlich. Je breiter ein Block ist, desto länger ist seine Laufzeit. In der Mitte der Abbildung sind zwei Funktionen, conv2_1 und conv2_2 zu sehen. Man erkennt, dass die Funktion conv2_2 hauptsächlich aus einer Schleife besteht, die mit For5 bezeichnet ist und die Laufzeit der Funktion dominiert. Die ermittelten Ausführungszeiten basieren auf einem Modell des eingesetzten Prozessors, so dass leicht ersichtlich wird, welche Teile des Programms dessen Laufzeit auf dem Zielsystem bestimmen und wo es sich folglich lohnt, mit der Parallelisierung zu beginnen.
Nachdem auf diese Weise schnell die kritischen Teile des Programms identifiziert sind, müssen nun unabhängige Tasks gefunden und ausgewählt werden, um sie auf die Kerne zu verteilen. In bestehendem Code werden meist Konstrukte eingesetzt, welche die Erkennung nebenläufiger Tasks behindern und somit deren parallele Verteilung erschweren. Hierzu gehören beispielsweise Zeiger und globale Variablen. Die Analyse und manuelle Restrukturierung solcher Programme für die Parallelisierung ist ein zeitraubendes und fehleranfälliges Unterfangen. Dieser Aufwand entfällt bei Verwendung von emmtrix Parallel Studio komplett, weil es die Abhängigkeiten zwischen den Tasks automatisch erkennt und dem Anwender grafisch anzeigt. Basierend auf dieser Analyse bekommt der Entwickler eine Auswahl an Transformationen angeboten, mit denen das ursprüngliche Programm so umstrukturiert werden kann, dass mehr Nebenläufigkeit entsteht. Der Entwickler wählt lediglich die Transformation aus. Die Umsetzung durch Umschreiben des Codes geschieht dann vollautomatisch durch emmtrix Parallel Studio, so dass sich hier keine Fehler einschleichen können. Ein wichtiger Baustein sind Schleifenoptimierungen.
Abbildung 4 Schleifentransformation
Abbildung 4 zeigt, wie sich die Transformation „Loop Splitting“ auf die Schleife For5 auswirkt: sie wird in zwei Schleifen For5 und For6 mit jeweils dem halben Iterationsbereich aufgeteilt, die später von verschiedenen Kernen ausgeführt werden können.
Abbildung 5 Feste Zuordnung von Tasks zu Kernen oder Ausschluss von Kernen von der Parallelisierung
Nachdem im vorherigen Schritt unabhängige Tasks identifiziert bzw. durch Transformationen geschaffen wurden, gilt es nun, diese so auf die Kerne zu verteilen, dass diese gut ausgelastet sind und möglichst wenige Daten zwischen den Kernen ausgetauscht werden müssen. Hierfür kommt ein automatischer Verteilungsalgorithmus zum Einsatz, der spezifische Eigenschaften der Zielarchitektur berücksichtigt. Er kennt den internen Aufbau des Prozessors, wie etwa die Anbindung von Speichern an die Prozessorkerne, und dessen Einfluss auf die Kommunikationskosten und somit die optimale Verteilung der Tasks. Beim AURIX™-Mikrocontroller sind beispielsweise die Kerne in zwei Cluster aufgeteilt. Der Datenaustausch zwischen Kernen verschiedener Cluster ist langsamer als zwischen Kernen eines Clusters. Deshalb sollten Tasks, die häufig Daten austauschen müssen, auf Kernen desselben Clusters verteilt werden. Auch wenn die Verteilung der Tasks zunächst vollautomatisch geschieht, kann der Entwickler in den Parallelisierungsprozess eingreifen, indem er Tasks an bestimmte Kerne heftet oder bestimmte Kerne von der Verteilung ausschließt. Dies geschieht wie in Abbildung 5 dargestellt über die grafische Benutzeroberfläche oder durch Annotationen im Eingangscode. Dadurch behält der Entwickler die volle Kontrolle und kann mit seinem Wissen über die Anwendung die Feinabstimmung des Ergebnisses übernehmen.
Abbildung 6 Abschätzung der Performanz des parallelen Programms
Nach Abschluss der Parallelisierung stellt sich die Frage, welche Beschleunigung durch die Parallelisierung erreicht wurde und ob die Anwendung nun die Anforderungen erfüllt. emmtrix Parallel Studio unterstützt den Entwickler bei der Analyse der parallelen Performanz durch Abschätzung der parallelen Laufzeit und der erreichten Beschleunigung sowie mit einer visuellen Darstellung des zeitlichen Programmablaufs wie in Abbildung 6 dargestellt. Die Abschätzung basiert auf dem Hardware- und Softwaremodell des Zielsystems und kann durch Simulation oder direkt durch Ausführung auf der Zielarchitektur verfeinert werden, so dass der Entwickler sofort ein Gefühl für die zu erwartende Beschleunigung bekommt.
Der Entwickler steuert diesen automatisierten Prozess durch seine Entscheidungen – das Anwenden von Transformationen und Festlegen von Kernen für bestimmte Tasks, ohne dass auch nur eine Zeile Code angefasst werden muss. Die eingesparte Implementierungszeit kann dazu verwendet werden, den Prozess mehrfach zu durchlaufen und die Auswirkungen verschiedener Entscheidungen auf die Performanz der Anwendung zu evaluieren. Dadurch kann ohne Spezialwissen über parallele Programmierung und das Zielsystem effizient und erfolgreich parallelisiert werden.
Am Ende dieses Prozesses erzeugt emmtrix Parallel Studio vollautomatisch korrekten parallelen Code für das gewählte Zielsystem, der auch die Kommunikation und Synchronisation zwischen den Kernen übernimmt. Dadurch werden Fehler, die bei der manuellen Parallelisierung typischerweise auftreten, von vorneherein ausgeschlossen – die zeitraubende Suche nach Deadlocks und Race Conditions entfällt.
Abbildung 7 Qualifizierung nach ISO 26262 und DO-178C - emmtrix Safety Kit
Bei der Qualifizierung paralleler Systeme nach ISO 26262 oder DO-178C gibt es einige zusätzliche Hürden, sowohl bei der Hardware als auch bei der parallelen Software. So ist der Infineon AURIX™ ist einer der wenigen Mehrkern-Mikrocontroller, der für funktional sichere Systeme nach ASIL D zertifiziert ist. Der Nachweis der funktionalen Sicherheit ist speziell für manuell geschriebene parallele Software schwer zu erbringen, denn allein die Abwesenheit von Deadlocks und Race Conditions, die unter Umständen nur sporadisch zu fatalen Fehlern führen können, ist selbst mit ausgiebigen Tests nicht mit letzter Sicherheit nachzuweisen. Hier setzt das emmtrix Safety Kit an: es liefert einen formalen Beweis, dass der automatisch generierte parallele Code mit dem ursprünglichen Code funktional identisch ist. Dadurch ist sichergestellt, dass die parallele Anwendung denselben Sicherheitsansprüchen genügt wie das qualifizierte Ursprungsprogramm.
Haben wir Ihr Interesse geweckt?
Dann nehmen Sie doch Kontakt zu uns auf! Wir unterstützen Sie gerne bei Ihrem nächsten Multicore-Projekt. Am 05. und am 19. November 2020 bieten wir Ihnen ein kostenloses AURIX™ Webinar auf Englisch an, bei dem wir beispielhaft an einer Anwendung demonstrieren, wie einfach es mit Hilfe von emmtrix Parallel Studio ist, Software für Infineon 32-bit TriCore™ AURIX™ TC2xx und TC3xx Mikrocontroller zu parallelisieren und dadurch die volle Leistung des Systems zu nutzen.
Hier geht es zur Anmeldung.
Michael Rückauer
Senior Engineer
emmtrix Technologies
________________________________________________________________________________________